Discover a powerful, end-to-end Machine Learning Model Development guide covering data collection, model training, evaluation, deployment, MLOps, and emerging AI trends. Learn how to build scalable, production-ready ML solutions with expert insights and real-world examples.
Machine Learning Model Development: From Concept to Production-Ready Solutions
Machine Learning Model Development has become a core capability for modern organizations. In a data-driven world, companies rely on ML models to generate insights, automate decisions, and create digital transformation at scale. Effective ML development requires a structured, end-to-end pipeline—from data collection to deployment—ensuring accuracy, reliability, transparency, and long-term maintainability.
-
Introduction
-
What Is Machine Learning Model Development?
-
Stage 1: Data Collection
-
Stage 2: Data Preprocessing
-
Stage 3: Feature Engineering
-
Stage 4: Algorithm Selection
-
Stage 5: Model Training
-
Stage 6: Model Evaluation
-
Stage 7: Hyperparameter Tuning
-
Stage 8: Model Deployment
-
Key Challenges in Machine Learning Model Development
-
Industry Applications
-
Emerging Trends
-
Best Practices
-
Conclusion
In today’s data-driven era, organizations across industries rely heavily on machine learning (ML) to extract actionable insights, automate decision-making, and unlock strategic value. Machine learning model development is no longer a purely academic exercise—it is a critical business capability that can drive operational efficiency, innovation, and competitive advantage.
Developing robust ML models requires a systematic, end-to-end approach, encompassing stages such as data collection, preprocessing, feature engineering, algorithm selection, model training, evaluation, and deployment. Beyond technical execution, developers must navigate challenges like bias, overfitting, and scalability while adopting emerging practices like AutoML, explainable AI (XAI), and MLOps.
This article provides a premium, high-level guide to machine learning model development, enriched with industry examples, practical insights, and advanced considerations for professional audiences.
Understanding Machine Learning Model Development
Machine learning models are algorithms that learn patterns from data to make predictions or decisions. Unlike rule-based programming, ML models adapt and improve over time based on experience. The development of these models requires strategic planning, rigorous testing, and operational deployment to ensure reliability, accuracy, and real-world applicability.
Key objectives of ML model development include:
- Prediction: Forecasting outcomes based on historical or real-time data.
- Classification: Categorizing data into predefined labels.
- Optimization: Enhancing processes or decisions based on objective criteria.
- Automation: Reducing human intervention in repetitive, data-intensive tasks.
Stage 1: Data Collection
The foundation of any successful ML model is high-quality data. Data must be relevant, representative, and sufficient to capture underlying patterns. Sources of data include:
- Internal datasets: CRM systems, ERP databases, transaction logs, sensor readings.
- External datasets: Public datasets, APIs, open data platforms.
- Generated datasets: Synthetic data for simulation or testing.
Best Practices:
- Ensure diverse, unbiased data to prevent skewed predictions.
- Collect structured and unstructured data (e.g., tabular, text, images, audio).
- Maintain data governance policies for privacy and compliance.
Example: A healthcare provider collects electronic health records, lab results, and medical imaging to train a predictive model for patient readmission risk.
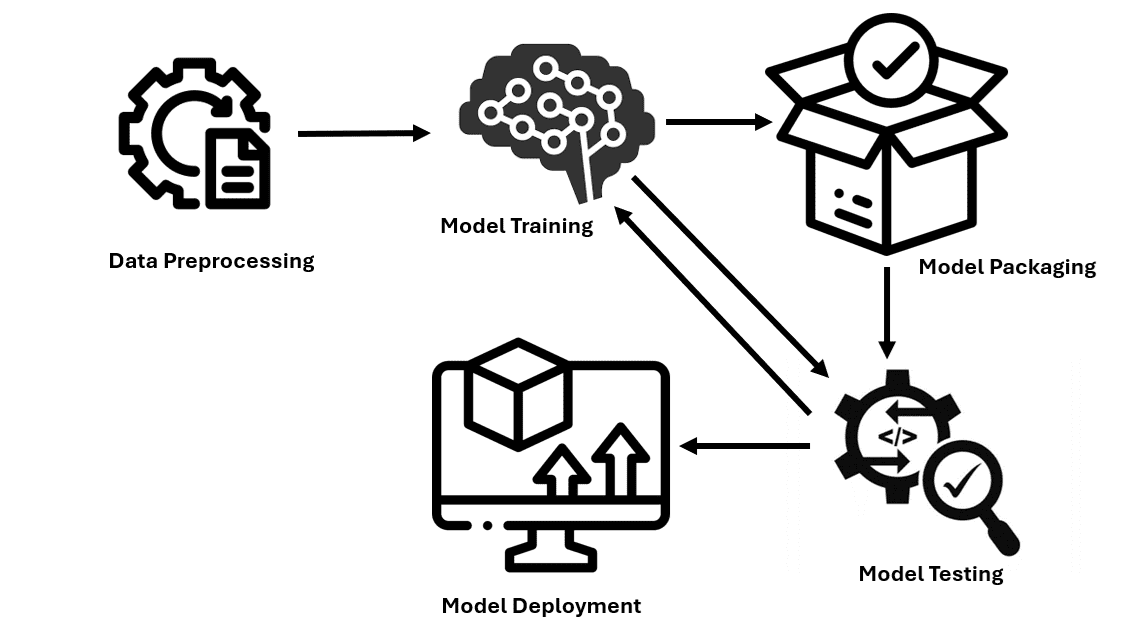
Stage 2: Data Preprocessing
Raw data often contains inconsistencies, missing values, and irrelevant features. Data preprocessing cleans and prepares the dataset for model training. This stage includes:
- Data cleaning: Handling missing values, removing duplicates, correcting errors.
- Normalization and scaling: Ensuring features are on comparable scales for algorithms like gradient descent.
- Encoding categorical variables: Converting text labels into numerical representations (e.g., one-hot encoding).
- Handling imbalanced data: Applying techniques like oversampling, undersampling, or synthetic data generation.
Example: In financial fraud detection, transactions labeled as fraudulent are rare. Preprocessing balances the dataset to avoid model bias toward non-fraudulent outcomes.
Stage 3: Feature Engineering
Feature engineering transforms raw data into informative inputs that improve model performance. Effective features capture underlying patterns and relationships in the data.
- Feature selection: Identifying the most relevant variables using statistical tests or model-based methods.
- Feature extraction: Creating new features from existing data, such as ratios, differences, or polynomial terms.
- Dimensionality reduction: Techniques like PCA reduce complexity while retaining essential information.
Example: In retail, combining product price, seasonal trends, and user demographics can generate predictive features for personalized recommendations.
Stage 4: Algorithm Selection
Choosing the appropriate algorithm depends on problem type, data characteristics, and business objectives. Common ML algorithms include:
- Supervised Learning: Linear regression, logistic regression, decision trees, random forests, gradient boosting, support vector machines, neural networks.
- Unsupervised Learning: K-means clustering, hierarchical clustering, PCA for pattern discovery.
- Reinforcement Learning: Q-learning, policy gradient methods for sequential decision-making.
Considerations:
- Model complexity vs. interpretability.
- Training speed and computational resources.
- Sensitivity to noise and outliers.
Example: In predictive maintenance, gradient boosting models are favored for their high accuracy, while simple decision trees provide better interpretability for engineers.
Stage 5: Model Training
Training involves exposing the algorithm to data so it can learn underlying patterns. Key aspects include:
- Training and validation split: Dividing data to assess performance and prevent overfitting.
- Loss function selection: Defining the objective the model seeks to minimize (e.g., mean squared error, cross-entropy).
- Optimization techniques: Gradient descent, stochastic gradient descent, and adaptive learning rates to improve convergence.
Example: Neural networks for image recognition undergo iterative training across thousands of labeled images, adjusting weights to minimize classification errors.
Stage 6: Model Evaluation
Model evaluation ensures predictions are accurate, robust, and generalizable. Metrics vary depending on the problem type:
- Regression: Mean squared error (MSE), root mean squared error (RMSE), R².
- Classification: Accuracy, precision, recall, F1-score, ROC-AUC.
- Clustering: Silhouette score, Davies-Bouldin index.
Best Practices:
- Use cross-validation for reliable performance estimates.
- Test on unseen, real-world data to simulate deployment scenarios.
- Monitor for bias, ensuring equitable predictions across populations.
Example: A healthcare ML model is evaluated using patient outcomes across multiple hospitals to confirm consistency and reliability.
Stage 7: Hyperparameter Tuning
Hyperparameters control model behavior and significantly impact performance. Techniques for optimization include:
- Grid Search: Exhaustive exploration of parameter combinations.
- Random Search: Sampling hyperparameter space randomly for faster results.
- Bayesian Optimization: Efficiently exploring parameter space based on prior results.
Example: Tuning learning rate, batch size, and tree depth in gradient boosting enhances predictive accuracy for loan default risk modeling.
Stage 8: Model Deployment
Deployment transitions models from experimental environments to production-ready systems. Key considerations:
- Scalability: Serving models efficiently for large volumes of requests.
- Monitoring and maintenance: Tracking model performance, drift, and retraining requirements.
- Integration: Embedding ML predictions into business applications and workflows.
Example: E-commerce companies deploy recommendation engines into their live platforms, updating models dynamically based on user interactions.
Common Challenges in Machine Learning Model Development
Despite methodological rigor, ML model development faces persistent challenges:
Overfitting
Occurs when a model memorizes training data rather than generalizing to new data. Mitigation strategies:
- Use cross-validation and regularization (L1/L2 penalties).
- Simplify model complexity.
- Augment training data.
Underfitting
Occurs when a model fails to capture underlying patterns. Solutions include:
- Selecting more sophisticated algorithms.
- Adding relevant features.
- Increasing training data volume.
Bias and Fairness
Models trained on biased data can perpetuate systemic inequities. Mitigation:
- Evaluate datasets for demographic representation.
- Apply fairness-aware algorithms.
- Continuously monitor and adjust deployed models.
Computational Constraints
Large-scale models require substantial processing power. Strategies:
- Utilize cloud-based GPU/TPU resources.
- Optimize algorithms and batch sizes.
- Apply model compression techniques.
Industry Applications of Machine Learning Models
Machine learning has transformative applications across sectors:
Healthcare
- Predictive diagnostics and risk stratification.
- Drug discovery acceleration.
- Patient engagement and virtual assistants.
Example: ML models analyze genomic data to suggest personalized treatment options for oncology patients.
Finance
- Fraud detection and anti-money laundering.
- Credit scoring and risk assessment.
- Algorithmic trading and portfolio optimization.
Example: Banks employ ML models to identify anomalous transactions in real time, reducing fraud losses significantly.
Retail
- Personalized recommendations and dynamic pricing.
- Inventory and demand forecasting.
- Customer sentiment analysis.
Example: Online marketplaces leverage ML to recommend products, increasing conversion rates and customer satisfaction.
Manufacturing
- Predictive maintenance for machinery.
- Quality assurance through computer vision.
- Supply chain optimization.
Example: Smart factories use ML to predict equipment failures, reducing downtime and maintenance costs.
Emerging Trends in Machine Learning Model Development

The field is advancing rapidly, introducing tools and methodologies that enhance productivity and model reliability:
Automated Machine Learning (AutoML)

AutoML frameworks simplify the development process by automating feature engineering, algorithm selection, and hyperparameter tuning, making ML accessible to non-experts.
Explainable AI (XAI)
As ML models become complex, interpretability is essential. XAI ensures stakeholders understand why a model made a specific prediction, critical for trust and regulatory compliance.
MLOps
MLOps combines machine learning with DevOps principles, ensuring reproducible, scalable, and maintainable ML deployment pipelines. It addresses monitoring, retraining, and model lifecycle management.
Real-Time and Edge ML
Processing data at the edge reduces latency, enhances privacy, and enables real-time decision-making, particularly in IoT and autonomous systems.
Best Practices for Successful ML Model Development
- Iterative Development: Adopt agile cycles to refine models continuously.
- Robust Data Management: Maintain high-quality, well-governed datasets.
- Cross-Functional Collaboration: Involve data engineers, domain experts, and business stakeholders.
- Continuous Monitoring: Track model performance, drift, and emerging biases.
- Ethical Considerations: Prioritize fairness, transparency, and privacy compliance.
Conclusion
Machine learning model development is a sophisticated, multi-stage process that requires technical expertise, domain knowledge, and strategic foresight. From data collection and preprocessing to training, evaluation, and deployment, each stage contributes to creating models that are accurate, scalable, and impactful.
Across industries—from healthcare and finance to retail and manufacturing—ML models are redefining how organizations make decisions, automate processes, and engage customers. Emerging trends like AutoML, XAI, and MLOps are further streamlining development, enabling enterprises to deliver production-ready, interpretable, and adaptive models at scale.
For professionals and organizations aiming to harness the full potential of machine learning, investing in structured, end-to-end model development is essential for achieving competitive advantage in the modern data-centric economy.